Geopositional encoding
Last year I published a paper at GISRUK with Prof Taylor Oshan, my collaborator at UMD. It was a great experience — he traveled over from the US, we got to enjoy a beautiful spring week in Bristol, and he introduced me to the UK GIS academic community.
There were lots of amazing talks at the event — one that has stuck with me was Prof Stef de Sabbata from Leicester sharing research on Geospatial Mechanistic Interpretability of Large Language Models. The research uses probing techniques and spatial autocorrelation analysis to show that LLMs encode geographic information in their internal representations — you can train a simple linear regression to predict coordinates of place names from the model's hidden states.
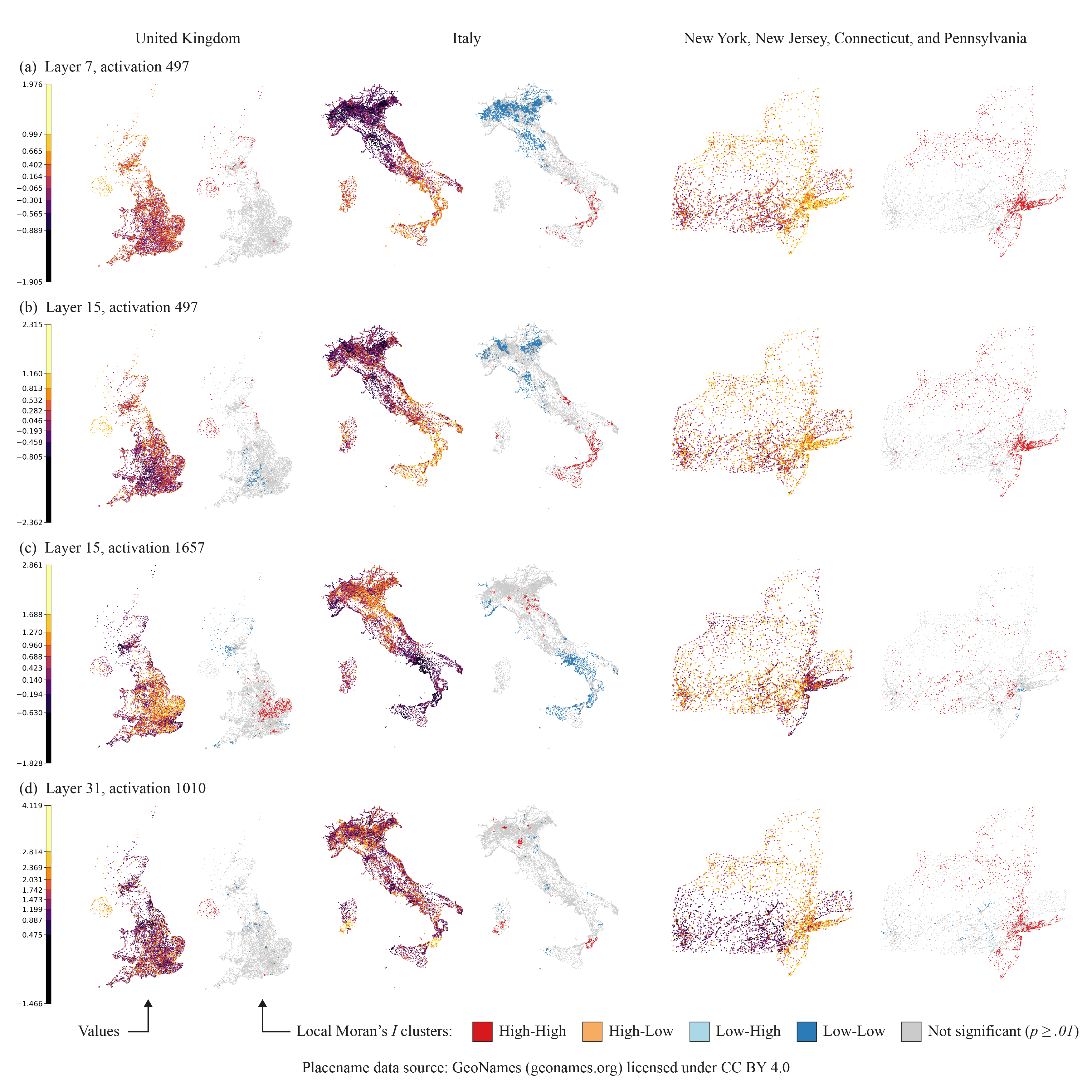
At the same time this is unsurprising and incredible, that spatial information is somehow reflected in our language and captured by these models. It builds on foundational work by Gurnee and Tegmark showing that LLMs learn linear representations of space and time, applying the broader framework of mechanistic interpretability — to my mind some of the most important research happening right now on AI alignment and safety. (A little dive into this world last year blew my mind.)
#Flip the script?
An idea that sprung to mind during Prof de Sabbata's talk: could this phenomenon be inverted to increase the spatial accuracy and improve contextual "understanding" within a model, to increase the likelihood it is responding about the right place? Could a geopositional encoding be injected into a prompt or internal state representation to increase the spatial accuracy of model output?
My hypothesis is that making location explicit through a structured encoding would help the model improve retrieval precision for geographically-situated knowledge.
I'd imagine the prompt would include geographic location — coordinates maybe, or some other way of representing the geographic subject of the prompt, a more reliable and explicit articulation of geography than natural language alone.
model.generate(
prompt="Tell me about activities in London",
location=(42.9849, -81.2453) # London, Ontario
)
// -> Output accurately reflects London, Ontario rather than
// defaulting to London, UK as the model might without encoding
There's precedent here: a positional encoding step is often applied to the vector embeddings passed into a transformer, to signal to the model where the token appeared in the input. The models learn this, and are able to more accurately attend to how ordering of tokens impacts semantic meaning of a sentence, and therefore output better next token predictions.
While researchers are extracting spatial representations from models (probing what's already there), I haven't found work on systematically injecting geopositional encodings into the input layer to improve geographic disambiguation and spatial reasoning in conversational contexts.
A perhaps separate, but related point: this is particularly relevant if we consider the potential of locally fine-tuned models adept at helping people based on immediate geographic context. We don't navigate the world with global maps — we zoom in, retrieving far more information about the local area (that is wildly irrelevant to the vast majority of map users).

The prediction that specialized models will yield efficiencies seems right: you don't need a customer service chatbot to understand quantum physics, and you don't need an LLM helping you navigate London to intimately understand the streets of Seoul. Passing user locations into inference calls might help models provide more accurate and relevant "local knowledge". (I say this may be separate because these locally tuned models would probably work differently than input-layer geopositional encoding — perhaps invoking locally fine-tuned models based on user locations rather than signaling location to a global model. Lots to think through.)
I've been meaning to dig into this more for quite some time — consider it on my "research backlog". If anyone is working on this, knows of research into it, or wants to run some experiments, I'd love to hear about it.
